
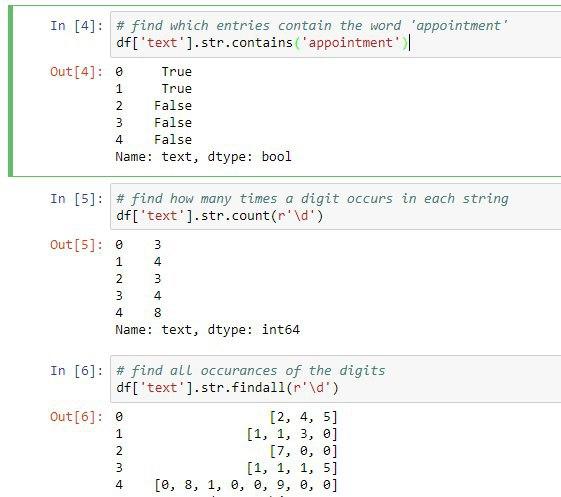
برای اینکه متوجه گردیم رشته ورودی ما شامل یک کلمه خاص یا یک الگو می باشد میتوانیم از متد str.contains استفاده کنیم. مثال زیر رو ببنید:
df['text'].str.contains('appointment')
0 True
1 True
2 False
3 False
4 False
خوب در نتیجه مشخص شد رشته اول و دوم کلمه apppintment رو شامل میشود
متد بعدی برای str پیدا کردن تعداد الگوی خاصی در یک رشته می باشد. برای اینکار از تابع str.count استفاده میکنیم. در این مثال میخواهیم بدانیم چند عدد داخل یک رشته قرار دارد.
همانطور که در درس قبلی گفتیم از d برای پیدا کردن ارقام استفاده میکنیم.
df['text'].str.count(r'\d')
0 3
1 4
2 3
3 4
4 8
اگر به رشته ابتدایی ما توجه کنید مشاهده میکنید پنجمین رشته ما شامل 8عدد می باشد.
حالا اگر بخواهیم تعداد عددهای داخل یک رشته رو پیدا کنیم و بصورت لیست نمایش دهیم میتوانیم از متد str.findall برای اینکار استفاده کنیم
df['text'].str.findall(r'\d')
0 [2, 4, 5]
1 [1, 1, 3, 0]
2 [7, 0, 0]
3 [1, 1, 1, 5]
4 [0, 8, 1, 0, 0, 9, 0,]
اگر بخواهیم زمان رو بصورت ساعت و دقیقه در پرانتز بصورت جداگانه قید کنیم کافیه عبارت منظم مربوط را بصورت گروه بندی شده با استفاده از پرانتز استفاده کنیم
df['text'].str.findall(r'(\d?\d):(\d\d)')
برای اینکه بتوانیم در پایتون دو عدد را با هم جمع کنیم و در خروجی نمایش دهیم میتوانیم از کد زیر برای اینکار استفاده کنید.
# Python3 program to add two numbers
number1 = input("First number: ")
number2 = input("\nSecond number: ")
# Adding two numbers
# User might also enter float numbers
sum = float(number1) + float(number2)
# Display the sum
# will print value in float
print("The sum of {0} and {1} is {2}" .format(number1, number2, sum))
خروجی برنامه :
First number: 13.5 Second number: 1.54 The sum of 13.5 and 1.54 is 15.04
در چالش کد پایتون بفرست کد تخفیف بگیر، مخاطبین گرامی برای ما یک قطعه کد پایتون ارسال کردند و یک کد تخفیف 70 درصدی برای تهیه آموزش های سایت چالش پایتون برنده خواهند شد.
در این چالش دو تا از مخاطبین ما برنده شدند که کدهای ارسالی این دو دوست گرامی در ادامه قرار خواهیم داد.
برنده شماره یک : yousefnooredin
کد ارسالی: این برنامه تعدادی عدد از کاربر میگیرد و انرا مرتب میکند(بدون استفاده از تابع sort)
دریافت رایگان کد ارسالی
برنده شماره دو : امیرحسین صالحی
کد ارسالی: این کد پیاده سازی درخت تصمیم هست که در اون از هیچ یک از دستورات آماده ی پایتون استفاده نکردم و تمام الگوریتم ها رو خودم پیاده کردم .
دریافت رایگان کد ارسالی
نچه از گزارش اخیر مایکروسافت برمیآید، آن است که برنامهنویسان عاشق زبان پایتون هستند.
زبان برنامهنویسی پایتون با پیشیگرفتن از جاوا که زمانی زبان غالب برنامهنویسی بود، به دومین زبان پرطرفدار برنامهنویسی در گیتهاب (GitHub)، سایت متعلق به مایکروسافت برای بهاشتراکگذاری کدهای متنباز، تبدیل شد. پایتون اکنون موفق شده است جاوا را براساس تعداد مشارکتکنندگان در منبع پشتسر بگذارد و بر این مبنا، این زبان برنامهنویسی اکنون پس از جاوااسکریپت که از سال 2014 در رتبهی اول جا خوش کرده است، دومین زبان پرطرفدار بهشمار میآید. آمار ارائهشده براساس گزارش رتبهبندی Octoverse برای سال 2019 بهدست آمده است. کسب رتبهی دوم در این سایت نقطهی عطف بزرگی برای پایتون 30 ساله است که خالق آن، خیدو فنروسوم (Guido van Rossum)، در همین هفته و پس از ترک سِمَت خود در شرکت ذخیرهسازی کلاد دراپباکس (Dropbox)، اعلام بازنشستگی کرد. بیشتر خدمات پیشرفته و اپلیکیشنهای دسکتاپ این شرکت با استفاده از پایتون نوشته شدهاند. جنبهی جالب دیگر گزارش گیتهاب، رتبهبندی زبانها براساس سرعت رشد آنها است. زبان برنامهنویسی دارت گوگل و فریمورک فلاتر که برای تولید رابطهای کاربری برای برنامههای تحت اندروید و iOS کاربرد دارد، بیشتر از سایر زبانها مدنظر برنامهنویسان در گیتهاب قرار گرفته است. در سالهای 2018 و 2019، دارت از بیشترین رشد برخوردار بوده و استفاده از آن در میان برنامهنویسان، 532 درصد بیشتر شده است. همچنین، زبان راست (Rust) موزیلا با رشد چشمگیر 235 درصد، پس از دارت در رتبهی دوم قرار دارد. نمودار زبانهای برنامهنویسی برتر در گیتهاب در پنج سال گذشته بیانگر افزایش محبوبیت پایتون است.
نمودار زبانهای برنامهنویسی برتر در گیتهاب در پنج سال گذشته بیانگر افزایش محبوبیت پایتون است.
گیت هاب اکنون از 40 میلیون توسعهدهنده میزبانی میکند پایتون محبوبترین زبان برنامهنویسی 2019 لقب گرفت زبان برنامهنویسی جاوا 13؛ ابزاری برای بهرهوری بیشتر برنامهنویسان
زبان برنامهنویسی راست برای برطرفکردن باگهای امنیتی مرتبط با حافظه طراحی شده که رایجترین نقص امنیتی در نرمافزارهای مایکروسافت در یک دههی گذشته بوده است؛ بههمیندلیل، مایکروسافت آن را در پایگاه کدهای ویندوز خود استفاده و آزمایش میکند. سال گذشته، زبان برنامهنویسی کاتلین، زبان تأییدشدهی گوگل برای تولید برنامههای اندرویدی، بیشترین روند رشد را در گیتهاب تجربه کرد؛ اما با وجود رشد 182 درصدی در طول سال، دیگر در میان 10 زبان برتر 2019 مشاهده نمیشود. زبان تایپاسکریپت هم که مایکروسافت از آن پشتیبانی میکند و یکی از مجموعههای مافوق جاوااسکریپت بهشمار میآید، با 161 درصد رشد سریعی در سال گذشته تجربه کرد. دلیل رشد سریع این زبان برنامهنویسی را میتوان به تعداد زیاد برنامهنویسانی نسبت داد که از آن برای دستوپنجه نرمکردن با برنامههای بزرگ نوشتهشده با جاوااسکریپت استفاده میکنند. زبانهای دیگری که درزمرهی 10 زبان دارای بیشترین سرعت رشد در سالهای 2018 و 2019 قرار میگیرند، عبارتاند از: اچسیال، پاورشل، اپکس، پایتون، اسمبلی و گو (Go). دارت: 532 درصد راست: 235 درصد اچسیال: 213 درصد کاتلین: 182 درصد تایپاسکریپت: 161 درصد پاورشل: 154 درصد اپکس: 151 درصد پایتون: 151 درصد اسمبلی: 149 درصد گو: 147 درصد قهرمان اصلی گزارش گیتهاب پایتون است که محبوبیتش را مدیون طرفداران علوم دادهای و علاقهمندان به سرگرمی و غنای کتابخانههای علوم دادهای، مانند نامپای است که این فرصت را دراختیار برنامهنویسان قرار داد تا کدهای پایتون را برای امور مربوط به یادگیری ماشین بهکار بگیرند. بخشی از انگیزهی مایکروسافت برای راهاندازی دورههای رایگان آموزش برنامهنویسی با پایتون در ماههای گذشته، جلب توجه برنامهنویسان به خدمات هوش مصنوعی آن در آژور است. یکی دیگر از نشانههای رونق علوم دادهای در گیتهاب، رشد نوتبوکهای ژوپیتر است که محیطی برای نوشتن و اجرای کدها با پشتیبانی از پایتون و آر و جولیا است.
خیدو فنروسوم، خالق زبان برنامهنویسی پایتون، هفتهی گذشته بازنشسته شد. علاوهبر آنچه گفته شد، گیتهاب در چند سال گذشته روی مسئلهی امنیت نیز سرمایهگذاری و توجه زیادی به کمک به برنامهنویسان برای یافتن و برطرفسازی آسیبپذیریها در کتابخانههای نرمافزاری متنباز یا نرمافزارهای وابسته به آنها کرده است. مسئولان شرکت میگویند هشدار آنها به برنامهنویسان موجب ترمیم بیشاز 7٫6 میلیون وابسته در همین سال شد. همچنین، این کار به انتشار بیش از 209 هزار ترمیم خودکار ازطریق سرویس رایگان Dependabot آن انجامیده است که ماه مه گذشته راهاندازی شد. بیش از 10 هزار همکار در بزرگترین پروژههای متنبازی که درحالحاضر در گیتهاب قرار دارند، مشغول همکاری هستند. بزرگترین پروژه تا زمان حال، ویژوال استودیو کد (Visual Studio Code) است که به محیط برنامهنویسی بسیار محبوبی برای برنامهنویسان فعال در پلتفرم گوگل تبدیل شده است. پروژهی ویژوال استودیو کد، 19،100 مشارکتکننده دارد. البته مایکروسافت پیش از آنکه شرکت گیتهاب را تصاحب کند، بزرگترین مشارکتکننده در پروژههای متنباز آن بهشمار میآمد. پروژههای دیگری که بیش از 10 هزار مشارکتکننده دارند، عبارتاند از: مستندسازی مایکروسافت آژور و فلاتر و فرست کانتریبیوشنز (First Contributions). نکتهی مهمی که در این گزارش بهچشم میخورد، مربوطبه متنبازبودن و استفادهی گیتهاب بهوسیلهی کشورهایی است که با تحریمهای آمریکا مواجه هستند. در ابتدای همین سال، گیتهاب دسترسی کاربران ساکن در کریمه و ایران را محدود کرد. این شرکت نمیخواهد کاری بیشتر از این انجام دهد که در قانون ایالات متحدهی آمریکا لازم دانسته شده است. در ژوئیه، گیتهاب به کاربران خود در کشورهای تحریمشده پیشنهاد کرد از سرور تجاری گیتهاب (GitHub Enterprise Server) استفاده کنند که نسخهی پولی و یکبار خرید (on-premise) این وبسایت برای میزبانی کدها بهصورت شخصی است؛ اما این وبسایت دیگر نمیتواند مجوز استفاده از محصول خود را بهصورت قانونی به کشورهای تحریمشده بفروشد. کاربران ساکن در کشورهای تحریمشده همچنان میتوانند در مخازن عمومی مشارکت کنند. در بخش سؤالها و جوابهای مطرحشده (FAQ) در سایت گیتهاب، دربارهی تحریمهای تجاری ایالات متحدهی آمریکا آمده است: سرور تجاری گیتهاب را نمیتوان به هیچکدام از کشورهای مندرج در فهرست کشورهای گروه E:1 در الحاقیهی شمارهی 1 تا بخش 740 در قسمت EAR یا به منطقهی کریمه واقع در اوکراین فروخت. این فهرست درحالحاضر شامل کشورهای کوبا، ایران، کرهشمالی و سوریه است؛ اما احتمال تغییر آن وجود دارد. این محدودیتها موجب بروز مشکلاتی در مسیر رشد گیتهاب شده است. دراینزمینه، در گزارش Octoverse آمده است: برنامهنویسان ایرانی دومین گروه با بیشترین نرخ رشد در پروژههای متنباز ایجادشده در مخازن عمومی گیتهاب هستند.
در ژوئیه، گیتهاب به کاربران خود در کشورهای تحریمشده پیشنهاد کرد از سرور تجاری گیتهاب (GitHub Enterprise Server) استفاده کنند که نسخهی پولی و یکبار خرید (on-premise) این وبسایت برای میزبانی کدها بهصورت شخصی است؛ اما این وبسایت دیگر نمیتواند مجوز استفاده از محصول خود را بهصورت قانونی به کشورهای تحریمشده بفروشد. کاربران ساکن در کشورهای تحریمشده همچنان میتوانند در مخازن عمومی مشارکت کنند. در بخش سؤالها و جوابهای مطرحشده (FAQ) در سایت گیتهاب، دربارهی تحریمهای تجاری ایالات متحدهی آمریکا آمده است: سرور تجاری گیتهاب را نمیتوان به هیچکدام از کشورهای مندرج در فهرست کشورهای گروه E:1 در الحاقیهی شمارهی 1 تا بخش 740 در قسمت EAR یا به منطقهی کریمه واقع در اوکراین فروخت. این فهرست درحالحاضر شامل کشورهای کوبا، ایران، کرهشمالی و سوریه است؛ اما احتمال تغییر آن وجود دارد. این محدودیتها موجب بروز مشکلاتی در مسیر رشد گیتهاب شده است. دراینزمینه، در گزارش Octoverse آمده است: برنامهنویسان ایرانی دومین گروه با بیشترین نرخ رشد در پروژههای متنباز ایجادشده در مخازن عمومی گیتهاب هستند.
دراین درس میخواهیم نگاهی به داده های متنی و کار با کتابخانه pandas بپردازیم.
ابتدا بصورت زیر یک داده متنی معرفی خواهیم کرد .و قبل از معرفی داده، کتابخانه pandas رو ایمپورت میکنیم:
import pandas as pd
time_sentences = ["Monday: The doctor's appointment is at 2:45pm.",
"Tuesday: The dentist's appointment is at 11:30 am.",
"Wednesday: At 7:00pm, there is a basketball game!",
"Thursday: Be back home by 11:15 pm at the latest.",
"Friday: Take the train at 08:10 am, arrive at 09:00am."]
برای اینکه برای ستون این داده متنی، اسمی رو قرار بدهیم از تابع DataFrame بصورت زیر استفاده میکنیم
df = pd.DataFrame(time_sentences, columns=['text'])
df
در حال حاضر داده ما شامل یک ستون هست که هر سطر آن یک متن می باشد و هر ورودی ما شامل یک روز در هفته و همچنین یک یا دو ساعت و دقیقه در بین متن می باشد

❇️ با استفاده از ویژگی str میتوانیم به مجموعه ای از روش های پردازش رشته دسترسی پیدا کنیم.
برای مثال متد str.len نشان دهنده طول متن یا همان تعداد کارکترهای هر رشته می باشد.
df['text'].str.len()
دستور بالا برای ستون text از رشته ورودی ، طول هر رشته را محاسبه میکند و در خروجی چاپ میکند. دقت کنید این ستون شامل 5 سطر می باشد و برای هر سطر بصورت جداگانه تعداد کارکترها را نمایش خواهد داد.
0 46
1 50
2 49
3 49
4 54
❇️ حالا اگر بخواهیم بجای تعداد کارکتر، تعداد کلمات رو مشخص کنیم. کافیه ابتدا با متد str.split کلمات یک متن رو با استفاده فاصله بین کلمات جدا کنیم سپس برای محاسبه طول اقدام کنیم:
df['text'].str.split().str.len()
0 7
1 8
2 8
3 10
4 10
پس برای مثال رشته اول شامل 7 کلمه و 46 کارکتر می باشد.

در درس چهارم تصمیم داریم وارد یک محیط جدید کدنویسی به نام jupyter notebook شویم و کدهامون رو تو این محیط اجرا کنیم.
طریقه نصب و کار کردن تو این محیط رو قبلا در دوره یادگیری ماشین بصورت ویدئویی ضبط کرده بودیم و شما میتونید بصورت رایگان از طریق لینک زیر بهش دسترسی داشته باشید.
مشاهده ویدئو
در چند سال اخیر شبکه های GAN در مرز علم یادگیری عمیق قرار گرفته اند و مورد توجه بسیاری از محققان این حوزه قرار گرفته اند. در این دوره 2 ساعته، ابتدا بدون تمرکز بر مباحث تئوری این شبکه ها به ارائه ایده ها و مفاهیم آن ها خواهیم پرداخت و در پایان یکی از پروژه های معروف و جذاب مربوط به این شبکه ها، یعنی تولید تصاویر صورت انسان توسط شبکه های GAN را در پایتون پیاده سازی می کنیم. این دوره برای کسانی که به تازگی وارد دنیای یادگیری عمیق شده اند و کسانی که قصد شروع یادگیری شبکه های GAN را دارند مفید خواهد بود.
به مناسب فرا رسیدن ماه محرم، همکاران وب سایت چالش پایتون با همراهی مهندس محمدحسین امینی تصمیم گرفتند یک وبینار زنده آموزشی بصورت کاملا رایگان برگزار نمایند. زمان برگزاری این وبینار به زودی اطلاع رسانی خواهد شد. از شما مخاطبین عزیز تقاضا داریم جهت حمایت از این نذری آموزشی این وبینار رایگان را اطلاع رسانی نمایید.
ظرفیت ثبت نام : 100 نفر
لینک ثبت نام : https://evnd.co/yK8bU
در زبانهای برنامهنویسی، سرعت مفهوم ندارد؛ بلکه، معناشناسی» (Semantics) در برنامهنویسی معتبر شناخته میشود. اگر جامعه برنامهنویسی، قصد مقایسه عملکرد دو یا چند زبان برنامهنویسی را داشته باشند، لازم است تا سرعت اجرا، حافظه مصرفی و قدرت پردازشی لازم برای پیادهسازی و اجرای توابع یا عملکردهای خاص در زبانهای برنامهنویسی مختلف سنجیده شود.
پروژهای تحت عنوان benchmarks-game، مقایسه جامعی از عملکرد دو زبان جاوا و پایتون انجام داده است. برای مشاهده قابلیتهای آزمایش شده و معیارهای استفاده برای این مقایسه، میتوانید به لینک [
+] مراجعه کنید. در ادامه، خلاصهای از نتایج مقایسه عملکرد پایتون و جاوا ارائه شده است.
پایتون یا جاوا: مقایسه عملکرد با استفاده از قابلیت pidigits
| قابلیت | pidigits | |||
| زبان | زمان (ثانیه) | حافظه (کیلوبایت) | قدرت پردازشی (پردازنده 4 هستهای) | |
| پایتون نسخه 3 | 3.47 | 10,140 | 0% 1% 100% 0% | |
| جاوا | 3.07 | 39,680 | 99% 3% 0% 5% | |
پایتون یا جاوا: مقایسه عملکرد با استفاده از قابلیت regex-redux
| قابلیت | regex-redux | |||
| زبان | زمان (ثانیه) | حافظه (کیلوبایت) | قدرت پردازشی (پردازنده 4 هستهای) | |
| پایتون نسخه 3 | 17.64 | 444,704 | 51% 80% 27% 28% | |
| جاوا | 10.48 | 645,680 | 72% 87% 74% 68% | |
پایتون یا جاوا: مقایسه عملکرد با استفاده از قابلیت reverse-complement
| قابلیت | reverse-complement | |||
| زبان | زمان (ثانیه) | حافظه (کیلوبایت) | قدرت پردازشی (پردازنده 4 هستهای) | |
| پایتون نسخه 3 | 18.59 | 1,007,292 | 22% 29% 59% 21% | |
| جاوا | 3.27 | 740,524 | 44% 57% 84% 43% | |
پایتون یا جاوا: مقایسه عملکرد با استفاده از قابلیت binary-trees
| قابلیت | binary-trees | |||
| زبان | زمان (ثانیه) | حافظه (کیلوبایت) | قدرت پردازشی (پردازنده 4 هستهای) | |
| پایتون نسخه 3 | 81.03 | 451,324 | 95% 87% 86% 88% | |
| جاوا | 8.28 | 907,060 | 86% 90% 80% 77% | |
پایتون یا جاوا: مقایسه عملکرد با استفاده از قابلیت n-body
| قابلیت | n-body | |||
| زبان | زمان (ثانیه) | حافظه (کیلوبایت) | قدرت پردازشی (پردازنده 4 هستهای) | |
| پایتون نسخه 3 | 774.34 | 7,844 | 29% 0% 0% 72% | |
| جاوا | 21.94 | 35,588 | 100% 0% 1% 1% | |
توجه داشته باشید که عملکرد یک زبان برنامهنویسی تنها تابعی از سرعت اجرای برنامهها در آن زبان نیست؛ بلکه عواملی نظیر نحوه کد نویسی و پیادهسازی برنامه توسط برنامهنویسان و عملکرد کتابخانههای شخص سوم» (Third party)، نقش مهمی در تعیین عملکرد یک زبان برنامهنویسی در هنگام اجرای کد دارد.
نکته قابل توجه در نتایج نمایش داده این است که زبان جاوا، زمان پردازشی کمتری برای اجرای کدها، نسبت به زبان پایتون میطلبد. همچنین، جاوا قدرت پردازشی و حافظه به مراتب کمتری نسبت به پایتون مصرف میکند.
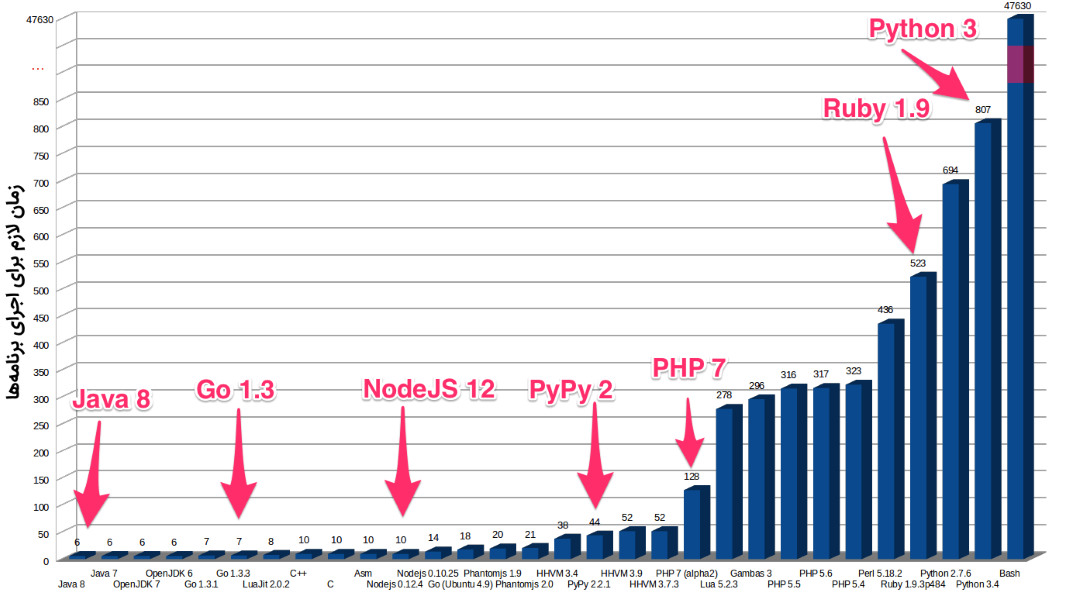
به طور کلی، در صورتی که روی پروژه برنامهنویسی کار میکنید که سرعت بهینه در اجرای آن بسیار حیاتی است، بهتر است که از زبان جاوا استفاده کنید. دلیل این امر، وجود مفسر به جای کامپایلر در زبان پایتون است. در زبانهایی که از مفسر استفاده میکنند، نوع دادهای متغیرها در زمان اجرا مشخص میشود. در نتیجه، سرعت اجرای کدها، به ویژه برای پروژههای بزرگ، کندتر از زبانهایی خواهد بود که از کامپایلر استفاده میکنند.
منبع : فرادرس
کتابخانه PIL که مخفف عبارت Python Imaging Library یا کتابخانه تصویر پایتون است، یکی از کتابخانههای پردازش تصویر با پایتون محسوب میشود. این کتابخانه، پشتیبانی از عملیات مرتبط با پردازش تصویر نظیر باز کردن، دستکاری و ذخیرهسازی تصاویر در فرمتهای مختلف را به زبان پایتون اضافه میکند. با این حال، توسعه آن از سال 2009 دچار وقفه شده است.
کتابخانه OpenCV که مخفف Open Source Computer Vision Library یا کتابخانه منبع باز بینایی کامپیوتر است، یکی از پراستفادهترین کتابخانههای برنامهنویسی برای کاربردهای بینایی کامپیوتر» (Computer Vision) محسوب میشود. کتابخانه OpenCV-Python، واسط برنامهنویسی کاربردی (API) برای
کتابخانه OpenCV در زبان پایتون محسوب میشود.
این کتابخانه نه تنها از سرعت بسیار بالایی برخوردار است (زیرا کدهای پیادهسازی آن توسط زبان C و C++ نوشته شده است)، بلکه کد نویسی برنامههای کاربردی مرتبط با پردازش تصویر با پایتون و بهکاراندازی (Deploy) آنها را تسهیل میبخشد. چنین ویژگیهایی، کتابخانه OpenCV-Python را به بهترین انتخاب جهت پردازش تصویر با پایتون و پیادهسازی برنامههای بینایی کامپیوتر در این زبان بدل کرده است (به ویژه اگر برنامههای بینایی کامپیوتر توسعه داده شده، به انجام محاسبات ریاضی پیچیده و سنگین نیاز داشته باشند) . در ادامه، برخی از فرایندهای پردازش تصویر با پایتون که توسط کتابخانه OpenCV-Python قابل انجام است، نمایش داده خواهد شد.
ترکیب تصاویر» (Image Blending): با استفاده از قابلیتی به نام هرم تصاویر» (Image Pyramid) در OpenCV-Python، میتوان تصاویر متناظر با یک سیب و یک پرتقال را با یکدیگر ترکیب و یک تصویر جدید درست کرد.
منبع : فرادرس
Scrappy یک کتابخانه محبوب پایتون برای web scraping است. از این کتابخانه برای ساخت خزنده استفاده میشود. در ابتدا از این کتابخانه تنها برای scraping استفاده میشد، اما بعدها مواردی مانند دادهکاوی، خودکارسازی تستها و. مورد استفاده قرار گرفت. Scrapy کتابخانهای متنباز و محبوب است.

ثبت نام
نکته : وبینار بصورت آنلاین در روز جمعه ۱۸ آبان ساعت ۱۴ تا ۱۶ برگزار خواهد شد.فیلم وبینار برای افرادی که در این بخش ثبت نام کردند ارسال خواهد شد. هر گونه سوالی در مورد وبینار داشتید میتوانید از طریق آی دی تلگرامی aiuni_admin ارسال کنید.
توضیحات دوره : در بسیاری از مواقع، هنگام کار با داده ها نیاز به کاهش ابعاد آن ها احساس می شود. یکی از راه های معروف و متداول کاهش ابعاد استفاده از تئوری معروف PCA می باشد. از دیگر کاربرد های معروف PCA می توان به استخراج اطلاعات مهم و کلیدی از داده ها اشاره کرد. در این وبینار ابتدا به معرفی تئوری PCA می پردازیم و سعی می کنیم مفاهیم آن را به خوبی درک کنیم. سپس به پیاده سازی پروژه کاهش حجم تصاویر و کد کردن آن ها توسط PCA می پردازیم.
گواهی آموزشی : در صورت ثبت نام و درخواست صدور گواهی آموزشی، برای افرادی که این نوع بلیت را تهیه کرده اند بدون برگزاری آزمون گواهی حضور در وبینار صادر و از طریق پست الکترونیکی ارسال خواهد شد. نمونه گواهینامه آموزشی در زیر مشاهده می کنید.

متد بعدی extract می باشد که میخواهیم رشته های رو استخراج کنیم که منطبق بر یک سری گروههای داخل پرانتز باشد. (مجددا تاکید میکنیم عبارت داخل پرانتز را بعنوان یک گروه در نظر میگیریم.)
در رشته ورودی اگر دقت کنیم میبینم زمان ها بصورت ساعت و دقیقه می باشد. تمام دقایق در این مثال ما بصورت دو رقمی بوده اما ساعت ممکن است یک رقمی یا دو رقمی باشد. پس عبارت منظم زیر رو برای پیدا کردن زمان در رشته و مجزا کردن آن در یک ستون دیگر استفاده میکنیم.
df['text'].str.extract(r'(\d?\d):(\d\d)')
0 1
0 2 45
1 11 30
2 7 00
3 11 15
4 08 1
عبارت منظم بالا در داخل یک پرانتز دو رقم رو در نظر خواهد گرفت اما علامت سوالی که در پرانتز اول وجود داره به این دلیل هست که اعلام کنه رقم اول میتونه باشه و میتونه هم نباشه که این مورد برای ساعت کاربرد داره.
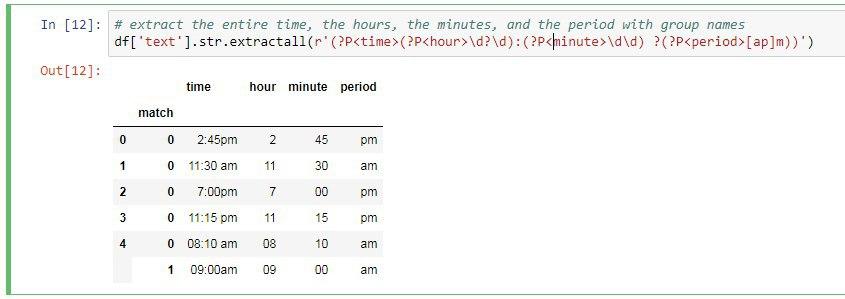
نکته ای که وجود داره اینه که در رشته پنجم ما دو تا زمان داشتیم اما فقط اولی رو چاپ کرد. برای این که مشکل رو رفع کنیم از متد extractall استفاده میکنیم و عبارت منظم رو هم طوری تغییر میدهیم که علامت pm یا am بعد ساعت هم در خروجی چاپ گردد.
حالا ما چهار تا گروه میخواهیم ایجاد کنیم گروه اول کل عبارت رو چاپ میکنه در واقع زمان رو چاپ میکنه و برای همین باید کل عبارت داخل پرانتز قرار بگیره. گروه دوم ساعت، گروه سوم دقیقه و گروه چهارم هم صبح یا عصر بودن رو چاپ خواهد کرد.
خروجی برنامه در تصویر بعدی قرار دارد.
اما یک نکته وجود علامت سوال قبل از مشخص کردن صبح یا عصر بودن هست.دلیل این مورد بخاطر وجود فاصله بین ساعت و pm یا am هست که در بعضی از رشته ها این فاصله وجود داره و در بعضی ها نبود و ما هم برای همین یک اسپس علامت سوال در نظر گرفتیم تا وجودش اامی نباشه و اختیاری باشه.

حالا در انتها اگر بخواهیم برای ستون ها ما نامی رو مشخص کنیم کافیه از همان نام گروه برای اینکار استفاده کنیم. برای ایجاد نام گروه از دستور زیر استفاده میکنیم:
و بجای GroupName هر نامی که دوست داشتید میتوانید قرار بدهید.
دقت کنید محل قرار گرفتن نام گروه بعد از پرانتز باز همان گروه می باشد.
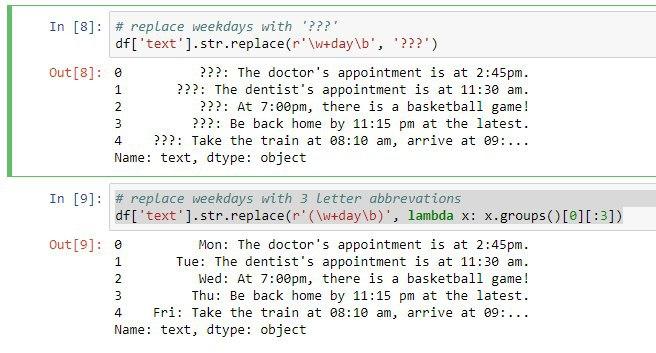
در مثال بعدی میخواهیم از دستوری برای جایگزینی استفاده کنیم بعنوان مثال هر جا روزی در هفته وجود داشت بجای آن روز، سه تا علامت سوال قرار بدهیم.
نکته ای که اینجا وجود داره اینه که تمام روزهای هفته ما به کلمه day ختم خواهد شد. در درس قبل گفتیم w برای تمام کارکتر ها استفاده میشه و b هم برای مشخص کردن مرز کلمه یا بعبارت بهتر پیدا کردن یک تطابق در ابتدا یا انتهای کلمه استفاده خواهد شد.
پس میتوانیم از عبارت نامنظم زیر و متد str.replace برای هدفمون استفاده کنیم:
df['text'].str.replace(r'\w+day\b', '???')
0 ???: The doctor's appointment is at 2:45pm.
1 ???: The dentist's appointment is at 11:30 am.
2 ???: At 7:00pm, there is a basketball game!
3 ???: Be back home by 11:15 pm at the latest.
4 ???: Take the train at 08:10 am, arrive at 09:
حالا اگر فرض بر این باشه بخواهیم تغییر در رشته ایجاد کنیم که بر مبنای کلمه مورد نظر باشه از متدهای replace و lambda استفاده خواهیم کرد. دقت کنید ما متد لامبدا رو در دوره مقدماتی توضیح داده بودیم.
حالا در این مثال میخواهیم بجای روزهای هفته، فقط سه حرف ابتداییش در خروجی قرار بگیره. مثلا بجای Monday عبارت Mon چاپ گردد.
df['text'].str.replace(r'(\w+day\b)', lambda x: x.groups()[0][:3])
0 Mon: The doctor's appointment is at 2:45pm.
1 Tue: The dentist's appointment is at 11:30 am.
2 Wed: At 7:00pm, there is a basketball game!
3 Thu: Be back home by 11:15 pm at the latest.
4 Fri: Take the train at 08:10 am, arrive at 09:
در کد فوق تابعی که با استفاده از لامبدا مشخص شده برای جدا کردن سه حرف اول روزها هفته است.
در واقع الگوی ما توسط عبارت منظم پیدا میشه و وقتی که داخل پرانتز قرار میدهیم اون رو تبدیل به یک گروه خواهیم کرد سپس توسط replace با سه حرف اول روزهای هفته جایگزین میکنیم.
در سال های اخیر، یادگیری عمیق، تحول بزرگی را در یادگیری ماشین و هوش مصنوعی ایجاد کرده است.دلیل اصلی نهفته در پس یادگیری عمیق» این ایده است که هوش مصنوعی» باید از مغز انسان الهام بگیرد.
در پیاده سازی پروژه ها از جدید ترین نسخه کتابخانه تنسورفلو یعنی (Tensorflow 2) و Keras استفاده شده است.
این آموزش توسط مهندس امینی دانشجوی ارشد برق دانشگاه صنعتی امیرکبیر با زبانی گویا و بصورت واضح بیان شده است.
⏰زمان : 5 ساعت 30 دقیقه
پروژه کاربردی که در این دوره پیاده سازی شده است:
▪️تخمین توابع با شبکه های Fully-Connected
▪️دسته بندی دیتاست Fashion MNIST با شبکه های SLP
▪️دسته بندی دیتاست MNIST Digits با شبکه های Fully-Connected
▪️دسته بندی دیتاست CIFAR-10 (ده نوع مختلف از اشیاء در تصاویر) با شبکه های CNN
☑️ کد تخفیف : nrz99
میزان تخفیف : 50 درصد
هزینه آموزش : 40000 تومان
لینک دوره : pythonchallenge.ir/deep_learning.html
آخرین مهلت استفاده : چهارشنبه 13 فروردین
کد تخفیف 50 درصدی : nrz99
مشاهده سرفصل و تهیه آموزش : pythonchallenge.ir
در این روزهای قرنطینه، بهترین فرصت برای افزایش دانش و استفاده از آموزش های کاربردی و پروژه محور و آماده شدن برای بازار کار می باشد.
⏰ فرصت استفاده : روز چهارشنبه 13 فروردین 1399
در این درس با کتابخانه pandas برای پردازش داده های متنی آشنا شدیم
این کتابخانه روشها و متدهای زیادی را برای پردازش داده های متنی دارد که با استفاد این روش ها و ترکیب ها قادر خواهیم بود برخی از پرازش های متنی بسیار قدرتمند رو با pandas انجام دهیم.
درباره این سایت